mysql 索引原理之记忆
相关的算法: https://www.cs.usfca.edu/~galles/visualization/xBST.html
二叉树
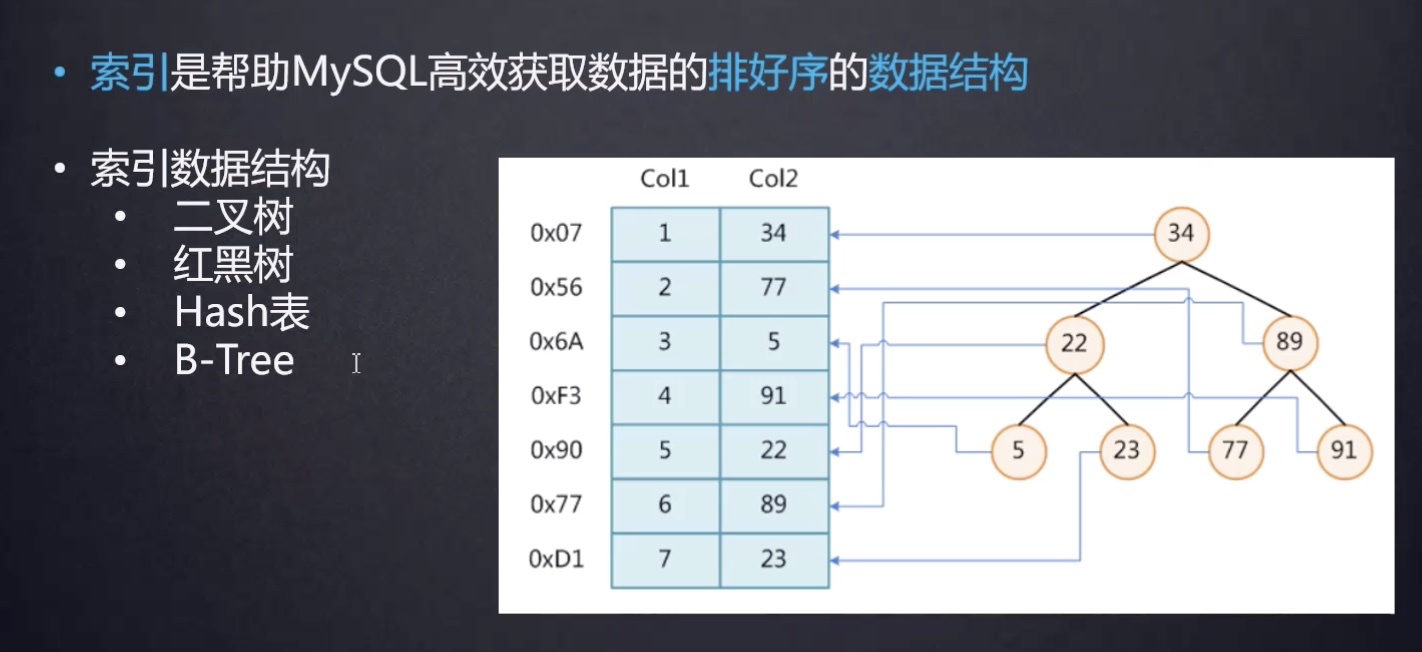
如上图,为二叉树的数据结构,但是二叉树并不是mysql 索引底层使用的数据结构。
原因是二叉树,在某些场景下会出现问题。比如下面这个场景,自增长的主键,数据二叉树只能从头开始遍历。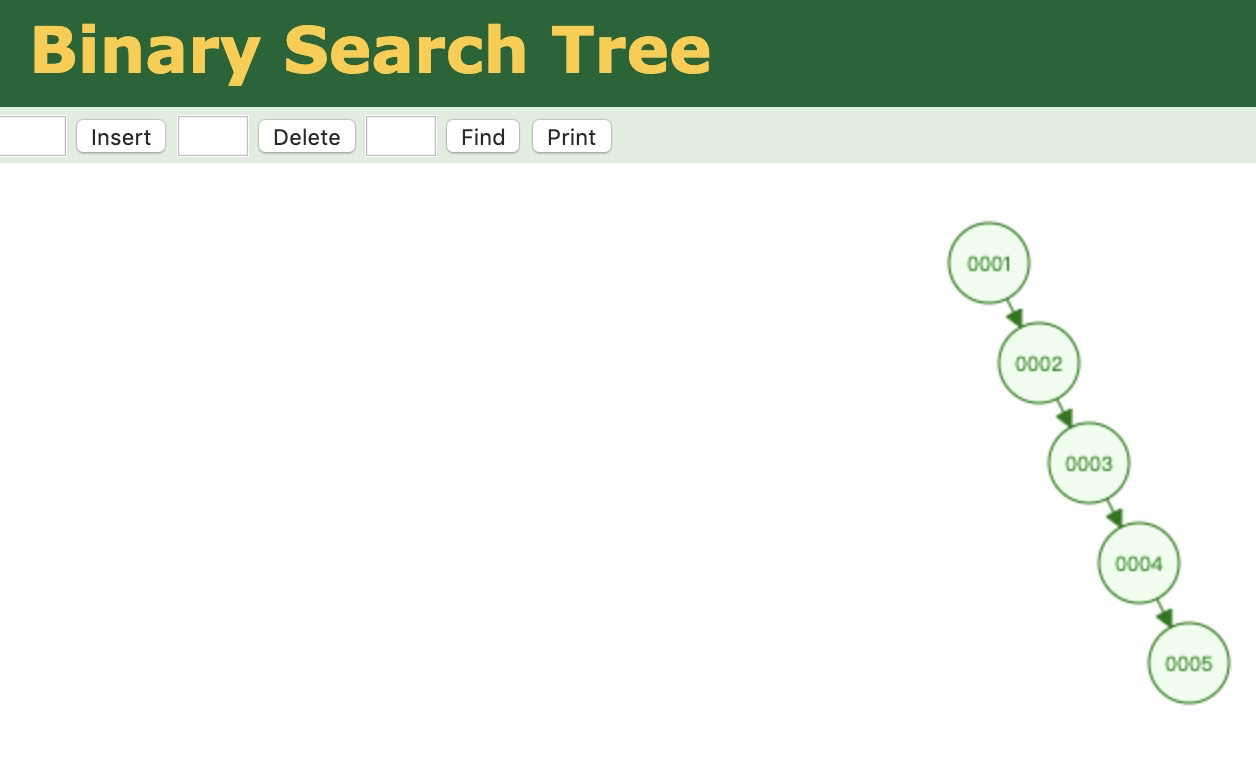
红黑树-二叉平衡树
- 自动调整高度,减少查找的深度。

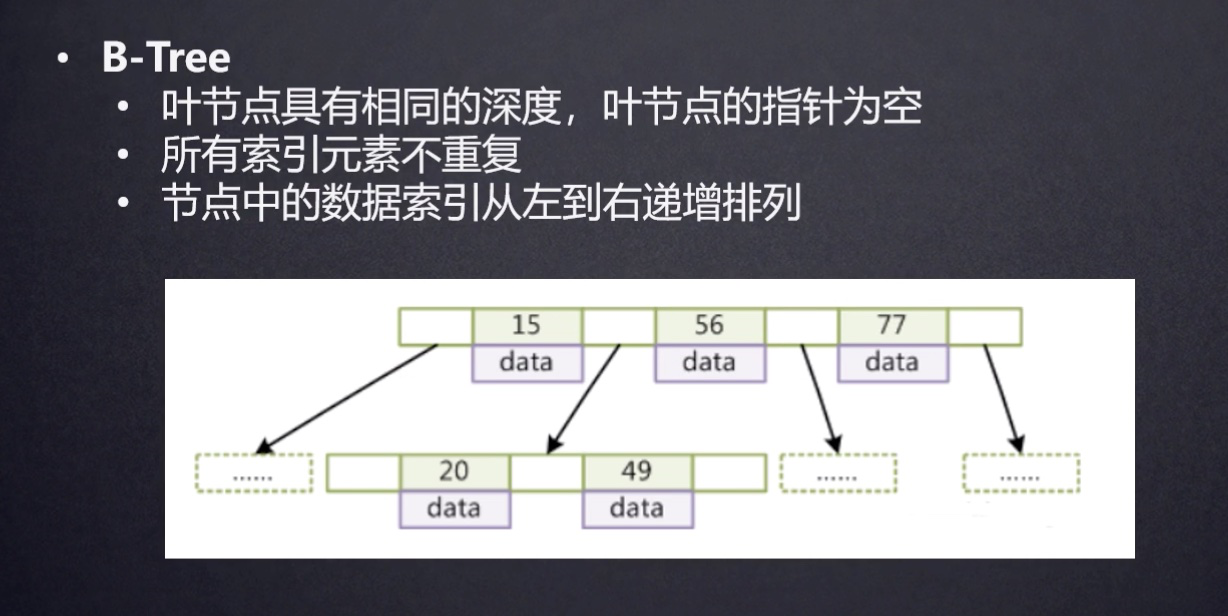
B-Tree
实际上,mysql 采用的上B+ Tree,B树的data也存储在节点上,占用了空间。下图中的特点,与B+Tree比对就很明显了。
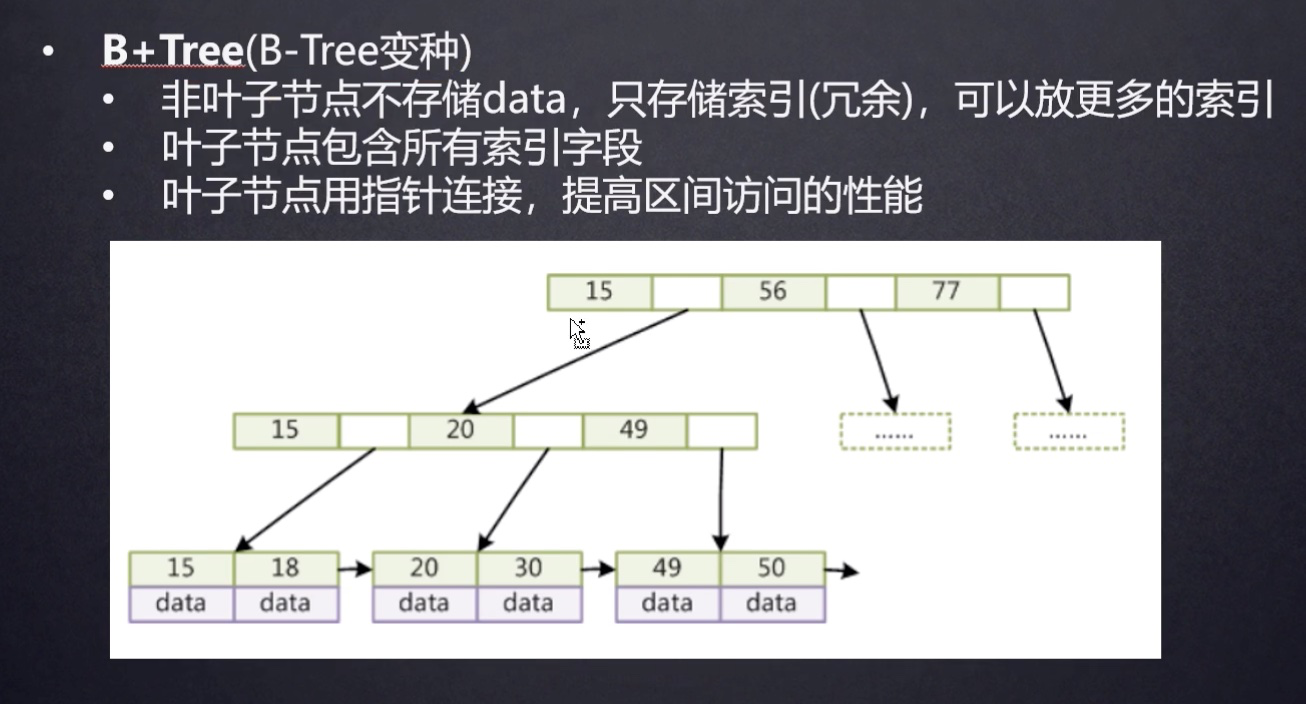
B+ Tree
Mysql 采用的是B+ Tree,
- 尤其注意叶子结点,包含所有的索引字段。所以如果查询的字段,仅包含索引字段,那么mysql是不用再次去磁盘读取数据的。
- 叶子结点之间是有双向指针的。所以查询where id > xx。这种情况是有帮助的。
- 如下图,查找select data from A where id =30. mysql 载入根节点后,从头开始遍历,发现30介于15与56之间,于是顺着地址再次从磁盘中取出下一个结点,15~49的索引。同理继续操作,直接在叶子结点中,查找到id=30的字段数据。
- 叶子结点之间的双向链指针,是为了应对where id between 28 to 30,这种场景。这样就不会回到上一个结点中,重新查找相邻结点了。这个也是为什么mysql还有一种索引类型-hash索引。hash 索引通过算法能直接定位到根节点,速度飞快,但是却无法应付范围查找。
组合索引
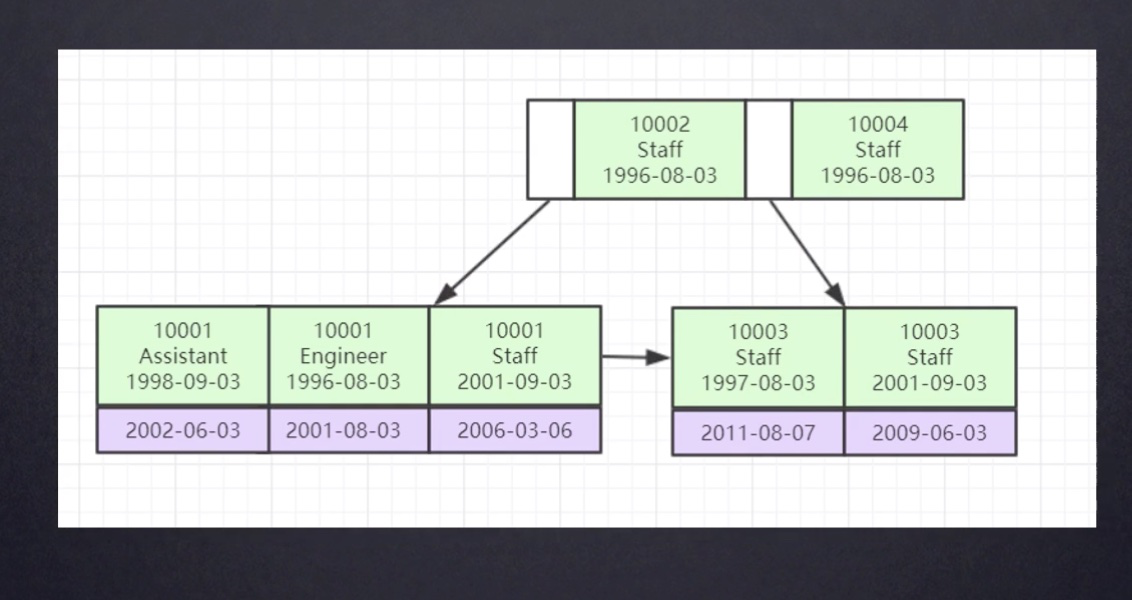
下图为组合索引的例子:(id, jobs, date), id从小到大递增,id相同时,按jobs从小到大排列,jobs相同时,再按date从小到大排列。所以mysql调优中的最左前缀原则, 比如下图中,有一个数据(10004,Assistant, 2002-03-01),那么它应该再叶子结点的最右侧。此时如果查找where name = Assistant。可见索引也排不上用场。