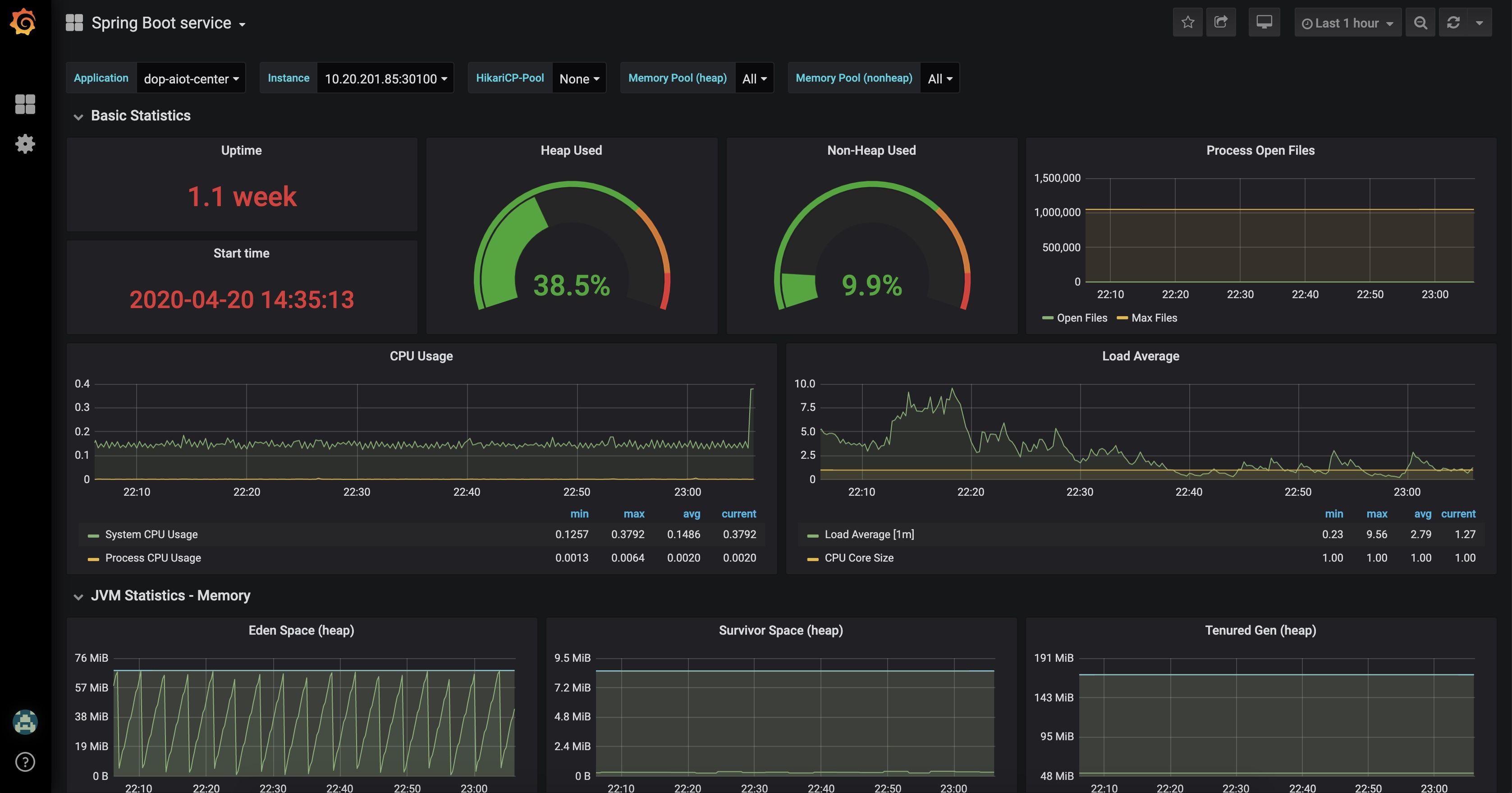
内部系统使用的一个AWS Elasticcache集群,不知不觉就扩容到8个node节点。被迫从AWS Elasticcache Redis上导出snapshot文件到S3,准备用作做分析。
分析工具是一个python实现的rbdtools
1 | pip install rbdtools |
实际上导出的中共有8个rbd文件,分析结果会生成csv文件。分析后,发现是大量登陆token,没有设置ttl。开发后续核对代码,才知道登陆时设置ttl了,但在更新权限时,忘记带上ttl值。于是日积月累产生越来越多无用的数据。
接下来就是清理了。
- 方案一:
取出没ttl的key的空闲时间,进行倒序排列,删除半年都没人访问的。
1 | redis-cli -c -h 10.20.0.111 -p 6379 --scan --pattern erpToken* | xargs -r -t -n1 redis-cli -c -h 10.20.0.112 -p 6379 object idletime |
- 方案二:
通过rename命令,变更key的name。后续再清理
- 方案三:
直接清空全部 key name 为erpToken* 模式的数据。
然而,此处有一个坑,redis-cli -c 的cluster 模式,并不会帮你跳转到所有节点
1 | redis-cli -c -h 10.20.0.118 -p 6379 --scan --pattern erpToken* |
其实 redis-cli 的 -c 参数,help如下:Enable cluster mode (follow -ASK and -MOVED redirections)。所以只是针对取特定值的时候,帮助做跳转而已。