http缓存,可不是简单的流量器与服务器通讯间的缓存机制。
其中还涉及正向代理,反向代理,CDN的缓存节点的行为。
缓存机制分为两种
强制缓存
流程: 浏览器发起请求,服务器返回response,respone header中的expired,表明这个资源的过期时间。后续再又请求时,就拿请求发起的时间与本地缓存文件的expired时间对比,没过期就直接展示给客户端。浏览器的F12。看到的就是(from disk cache)。
其中涉及两个响应头:
expired:
http1.0时代的产物,且客户端与服务器的时间不是一定一致,返回具体的时间戳,这种做法考虑的并不周全。于是后续就有了新的cache-control头。
这个expired ,曾经还遇到过一次故障,nginx上,开发将~* *.jpg设置为expired +30d。导致cdn缓存没有用上。比如图片A,在linux上的mtime 为Atime ,则返回的expired 头为 Atime +30d。 然而这个文件最后修改都好几个月前的事情了。
cache-control: private、public、no-cacheno-store、max-age,默认认为private。
private: 客户端可以缓存(仅仅浏览器缓存,代理服务器不缓存)
public: 客户端和代理服务器都可缓存
max-age=xxx: 缓存的内容将在 xxx 秒后失效(和private,public 结合一起使用)
no-cache: 需要使用对比缓存来验证缓存数据
no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发(很少用,除非明确不想让客户端缓存的资源)
下图中,便是例子,max-age单位为秒,采用默认的private,
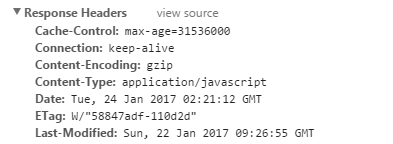
如果expires和cache-control同时存在,cache-control会覆盖expires。建议两个都写,cache-control是http1.1的头字段,expires是http1.0的头字段,都写兼容会好点。
对比缓存
采用本地浏览器缓存时,都会更服务器发起一个请求,问一下资源是否被更新了。
这里引申一点,在cdn的请求下,cdn也会向源站发起请求,用以对比缓存吗?
响应码:
* 200 代表服务器资源更新里,重新给你个新的。
* 304 代表服务器资源没更新,告诉浏览器你本地可以用,仅仅有响应头,没有数据体,也能减少服务器压力,以及传输带宽。
Last-Modified / If-Modified-Since
服务器第一次响应时,返回Last-Modified: 2020-02-01 23:00:00 ,标示资源的最后修改时间。
客户端下一次请求时,请求头,带上 If-Modified-Since: 2020-02-01 23:00:00。然后服务器判断后,返回200或是304
Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since)
服务器第一次响应时,返回Etag: xxxxxx,标示资源的维一标示,如果文件修改了Etag会更新。
客户端下一次请求时,请求头,带上Etag: xxxxxx。然后服务器判断后,返回200或是304
看到这里,那对比缓存与强制缓存,那个优先级更高呢🧐,毕竟上图中, 你看Etag,Cache-control,Last-Modified都全部返回啊。答案是做个实验呗。 或者参考别人的:
https://www.imooc.com/article/details/id/22841
2020/04/20更新:
如何快速辩证用的是 强制缓存还是对比缓存。从返回码就可以看到端倪。显示来自缓存,并且返回码是200的,这个就是对比缓存了。而304就是对比缓存了。